การใช้งาน Cloudera Hue
Hue คือ Web Interface สำหรับการ Query ข้อมูลใน Data Platform ด้วย Hive, Impala, Solr และ Spark
- Hue URL: https://dpc-cdr-u1.mea.or.th:8889/hue
- Hue Official Docs: Using Hue
การ Login เข้าใช้งาน
ดาวโหลด ติดตั้ง ตั้งค่า MIT Kerberos และ Firefox ให้เรียบร้อย
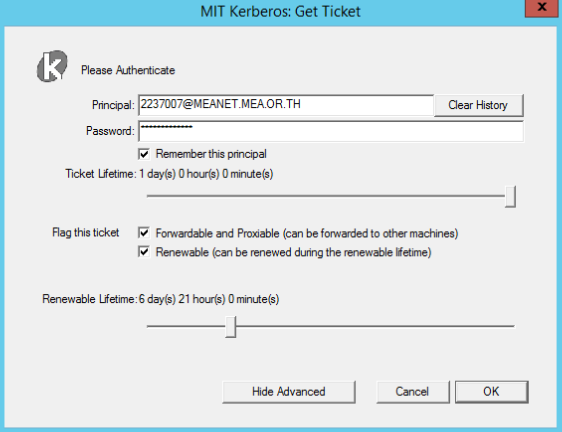
เปิดโปรแกรม MIT Kerberos Ticker Manager จากนั้นกดที่ปุ่ม Get Ticket กรอกข้อมูลตามรายละเอียดด้านล่าง และ กดปุ่ม OK
หัวข้อ ค่าที่กรอก รายละเอียด Principal รหัสพนักงาน@MEANET.MEA.OR.THรหัสพนักงานพร้อมโดเมน เช่น 2237007@MEANET.MEA.OR.THPassword รหัสผ่านที่ใช้กับระบบ ADใช้รหัสเดียวกับระบบ AD ของกฟน. (รหัสเดียวกับ WiFi) รูปตัวอย่าง
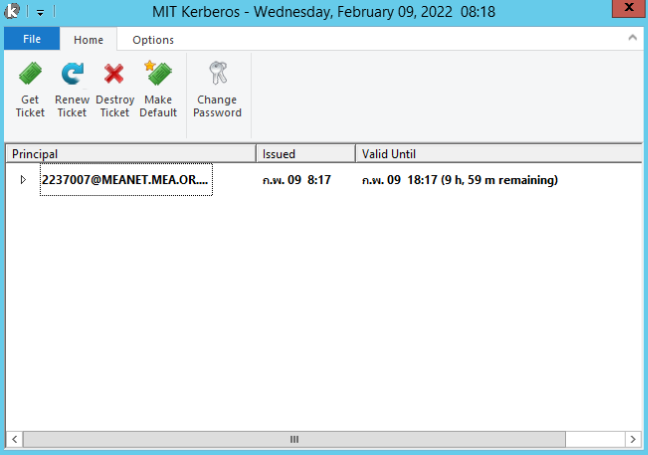
ถ้าทำถูกต้องคุณจะเห็น Ticket สำหรับเข้าใช้งาน Data Platform ตามรูป
การเข้าใช้งาน Hue
การใช้งาน Tools ต่างๆใน Data Platform จะต้องอยู่ภายใน Network ของ กฟน. เท่านั้น หากคุณทำงานจากบ้านจะต้องเชื่อมต่อกับ VPN ก่อนการใช้งาน
ใช้ Firefox เปิดไปที่เว็บไซต์ https://dpc-cdr-u1.mea.or.th:8889/hue
หน้าต่าง Hue มีส่วนประกอบหลักตามรูป
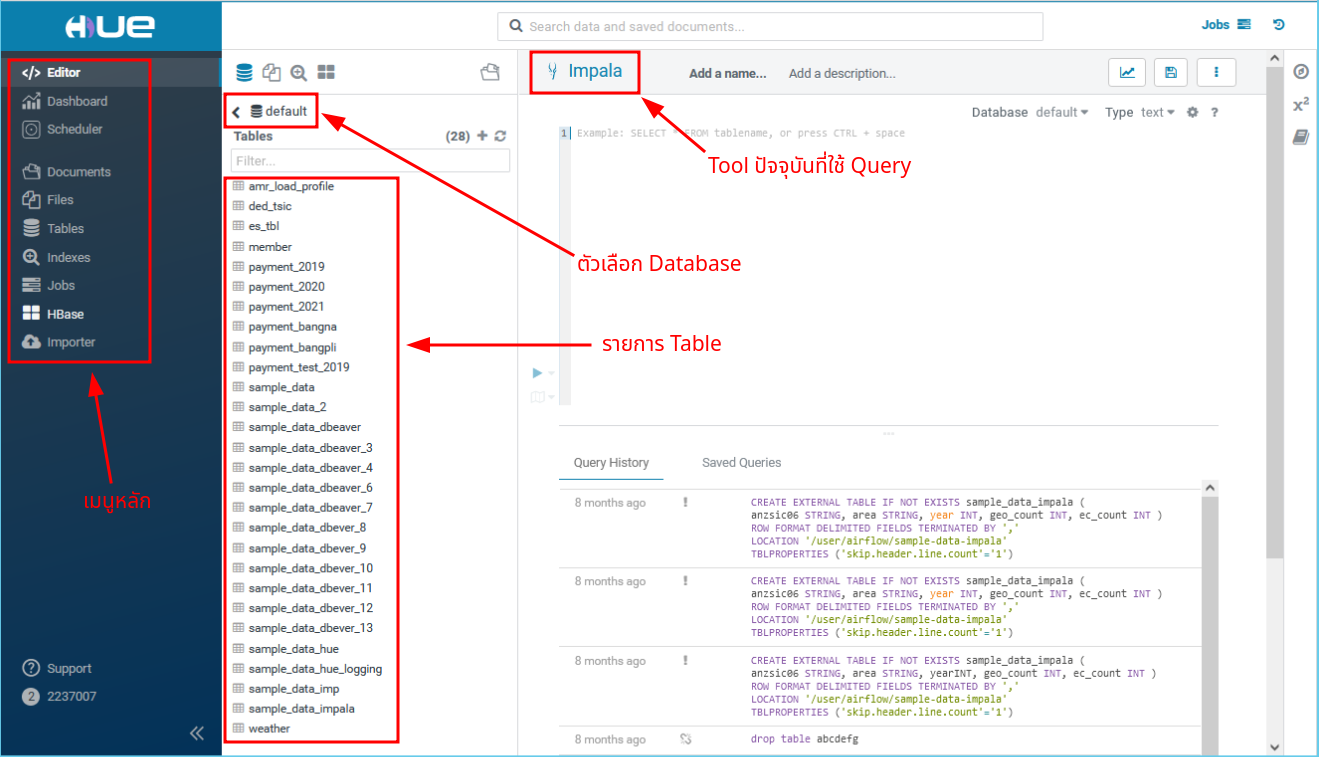
ให้คลิกที่ตัวเลือก Database และ เลือก Database ชื่อ
airflowคุณจะเห็นรายการ Table ข้อมูลทั้งหมดที่ Data Engineer ได้เตรียมไว้ ข้อมูลใน Hue นี้เหมาะสำหรับใช้ในการ Explore หาความสัมพันธ์ หรือ ศึกษาสภาพข้อมูลเชิงลึก และ ข้อมูลเหล่านี้อาจจะไม่เหมือนกับที่คุณเห็นใน Data Catalog เนื่องจากข้อมูลใน Data Catalog เป็นชุดข้อมูลที่ถูกกรองและพร้อมเผยแพร่ตามนโยบายแล้ว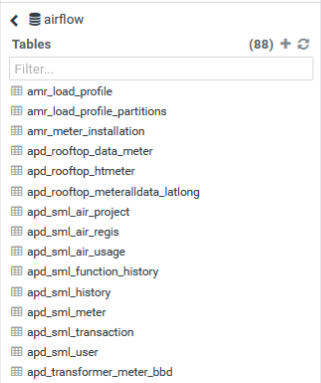
การ Query ด้วย Impala SQL
คุณจะได้เรียนรู้เกี่ยวกับพื้นฐาน SQL และ Impala ในหลักสูตร Data Scientist และ Data Engineering Bootcamp โดยสรุป Impala เป็น Tool ที่ช่วยให้คุณสามารถ Query ข้อมูลที่อยู่ใน Data Lake ด้วยภาษาคล้ายกับ SQL ได้อย่างรวดเร็ว ซึ่งโดยปกติจะ Interactive มากกว่า Hive
เลื่อนเมาส์ไปที่เมนูหลัก Editor จากนั้นเลือก Impala บนเมนูที่เด้งขึ้นมา
ที่ช่องสำหรับเขียน Code คุณสามารถทดลอง Query ข้อมูล Payment ปี 2021 ด้วยคำสั่ง SQL ด้านล่าง และ กดปุ่ม Play ตามตัวอย่างในรูป
สิทธิในการใช้งานคุณจะได้รับสิทธิ Query ตามนโยบายที่กำหนดเท่านั้น โดยปกตินักเรียนในหลักสูตร Data Engineering และ Data Scientist จะได้รับอนุญาตให้เข้ามาศึกษาข้อมูลใน Data Platform ได้โดยตรง สำหรับนักเรียนหลักสูตร Data Analyst จะได้รับสิทธิในการใช้ข้อมูลที่ผ่านการกรองใน Data Catalog เท่านั้น
SELECT * FROM airflow.idd_payment
WHERE year(clearing_date)=2021;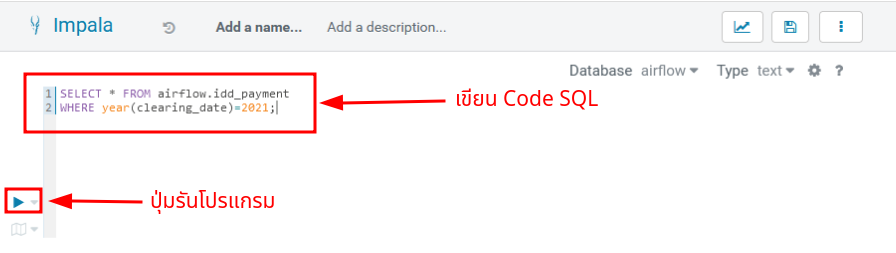
คุณจะได้ผลลัพธ์จากการ Query ตามรูป
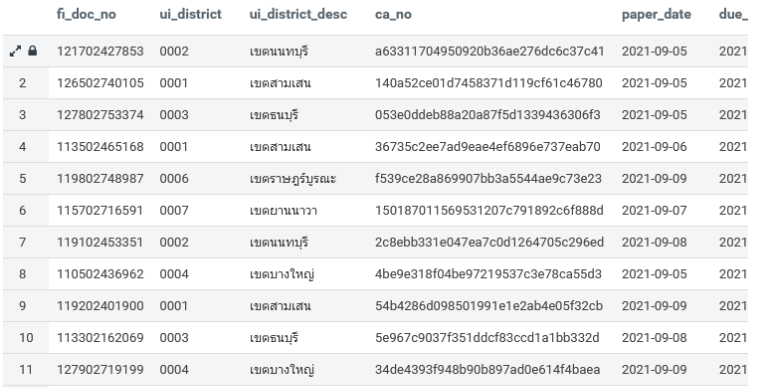
การ Query ด้วย HiveQL
คุณจะได้เรียนรู้เกี่ยวกับพื้นฐาน SQL และ Hive ในหลักสูตร Data Scientist และ Data Engineering Bootcamp โดยสรุป Hive เป็น Tool ที่ช่วยให้คุณสามารถ Query ข้อมูลที่อยู่ใน Data Lake ด้วยภาษาคล้ายกับ SQL Hive ของการไฟฟ้านครหลวงใช้ Apache Tez เป็น Engine ในการคำนวณทดแทน Map Reduce Hive เหมาะสำหรับงานในลักษณะ Batch ในขณะที่ Impala เหมาะกับงาน Ad-hoc
เลื่อนเมาส์ไปที่เมนูหลัก Editor จากนั้นเลือก Hive บนเมนูที่เด้งขึ้นมา
ที่ช่องสำหรับเขียน Code คุณสามารถทดลอง Query ข้อมูล Payment ปี 2021 ด้วยคำสั่ง SQL ด้านล่าง และ กดปุ่ม Play ตามตัวอย่างในรูป
สิทธิในการใช้งานคุณจะได้รับสิทธิ Query ตามนโยบายที่กำหนดเท่านั้น โดยปกตินักเรียนในหลักสูตร Data Engineering และ Data Scientist จะได้รับอนุญาตให้เข้ามาศึกษาข้อมูลใน Data Platform ได้โดยตรง สำหรับนักเรียนหลักสูตร Data Analyst จะได้รับสิทธิในการใช้ข้อมูลที่ผ่านการกรองใน Data Catalog เท่านั้น
SELECT * FROM airflow.idd_payment
WHERE year(clearing_date)=2021;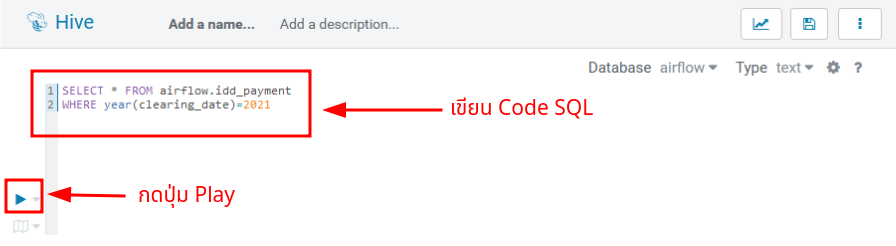
คุณจะได้ผลลัพธ์จากการ Query ตามรูป
การบริหารจัดการ HDFS
คุณสามารถอัพโหลด ดาวโหลด บริหารจัดการ ไฟล์ต่างๆบน HDFS ผ่าน Hue Web UI ได้ดังนี้
ที่เมนูหลักคลิกที่ Files
คุณจะเห็นหน้าต่าง File Browser ตามรูป ซึ่งคุณสามารถบริหารจัดการได้เหมือนไฟล์ทั่วไป
สิทธิการใช้งานคุณมีสิทธิ Read/Write เฉพาะในไดเรกทอรี่ของคุณเท่านั้น ในกรณีที่ต้องการทำงานเป็นทีมผ่านไดเรกทอรี่อื่น คุณสามารถแจ้งขอเพิ่มสิทธิได้ที่ Google Form
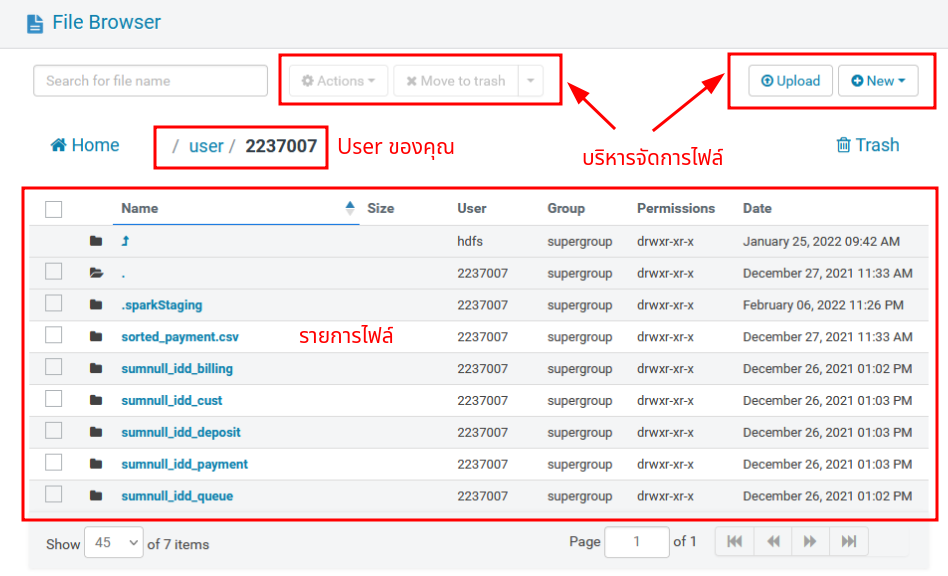
คุณสามารถ Interface กับ HDFS ด้วยการเขียนโปรแกรมผ่านช่องทางอื่นๆ เช่น Apache Airflow, Apache Spark หรือ HDFS CLI
การ Submit Spark Applications
หลังจากที่คุณเขียน Spark Application เรียบร้อยแล้วคุณสามารถนำโปรแกรมมารันบน Hue ได้ตามขั้นตอนดังนี้
ที่เมนูหลักคลิกที่ Editor แล้วเลือก Spark บนเมนูที่เด้งขึ้นมา
ทดสอบด้วยการสร้างโปรแกรม PySpark บนเครื่องของคุณ และเซฟเป็นชื่อ
pi-estimation.pyPySpark Examplesคุณสามารถศึกษาโปรแกรมตัวอย่างของ PySpark ได้ที่ Spark Github
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()ที่หน้าต่าง Spark คลิก
+ที่ Libs และ กดปุ่ม...เพื่อเลือกโปรแกรม PySpark ที่จะรัน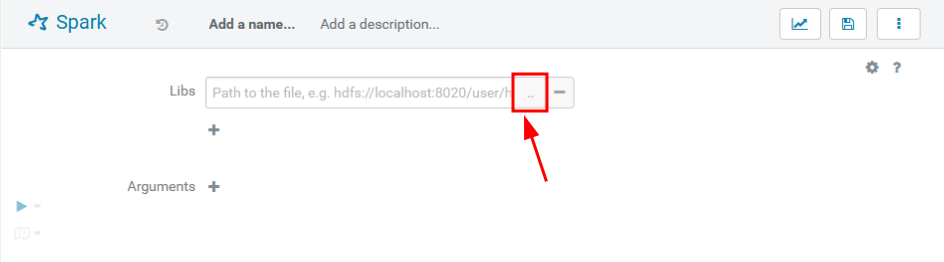
ที่หน้าต่างเลือกไฟล์ กดปุ่ม Upload a file เลือกไฟล์
pi-estimation.pyที่สร้างไว้ในข้อ 2 จากนั้นคลิกที่ชื่อไฟล์ในหน้าต่าง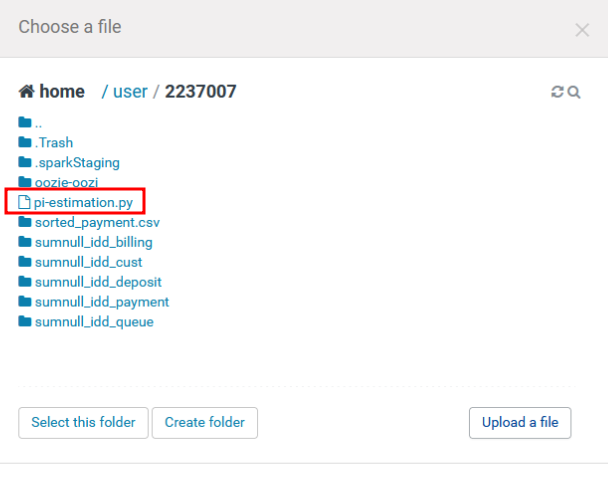
เนื่องจากโปรแกรม
pi-estimationมี Argument ที่จะต้องกรอก คุณสามารถกรอก Argument ที่โปรแกรมต้องการด้วยการคลิกที่+ข้างข้อความ Arguments จากนั้นกรอก Argument ที่ต้องการ ในกรณีนี้เราจำเป็นต้องใส่จำนวน Partitions ด้วยค่า10เพื่อทำการประมาณค่า Pi ตามรูป เมื่อเรียบร้อยแล้ว กดปุ่ม Play เพื่อรันโปรแกรม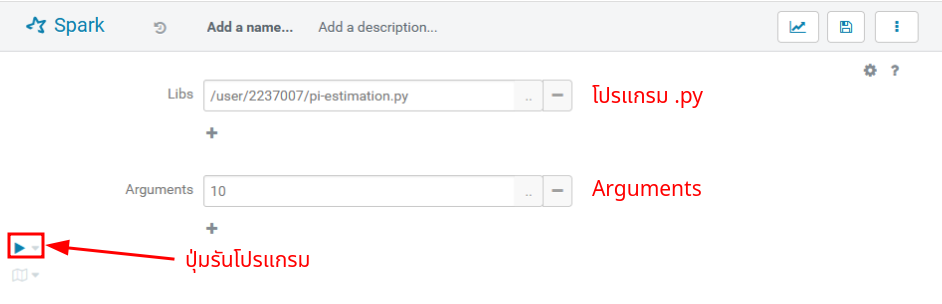
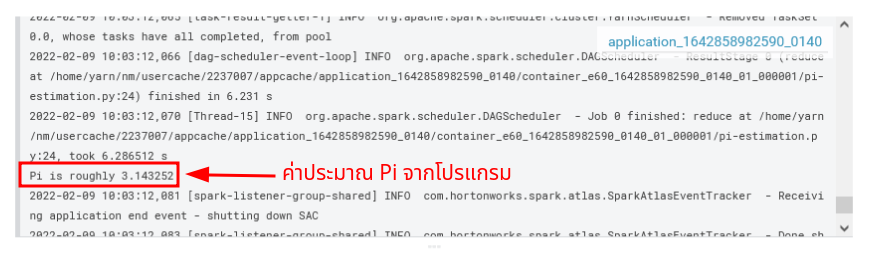
เมื่อโปรแกรมรันเสร็จแล้วให้เลื่อน Log ลงมาดูผลลัพธ์ โดยปกติจะอยู่ท้ายๆ Log ตามรูป (อาจจะหายากนิดหน่อย เนื่องจาก Spark จะ Output ขั้นตอนการคำนวณด้วย)